TotalCommander-ов додатак за PDF датотеке
 pdfOCR је додатак (eng. plugin) за TotalCommander. Овај додатак приказује у TotalCommander-у да ли PDF датотеке треба да се обраде помоћу OCR софтвера или су већ обрађене.
pdfOCR је додатак (eng. plugin) за TotalCommander. Овај додатак приказује у TotalCommander-у да ли PDF датотеке треба да се обраде помоћу OCR софтвера или су већ обрађене.
Наиме кад радите са PDF датотекама које сте сами направили или сте их добили с Интернета, вероватно најважнија ствар коју можете да урадите јесте да проверите да ли су оне у облику погодном за претраживање текста или су у облику скенираних слика. PDF који је скениран непогодан је за претраживање како унутар Adobe Reader читача, тако и у свим другим софтверима који претражују PDF датотеке. Самим тим док се PDF датотека не учини читљивом за претраживаче ове датотеке се не могу укључити ни у какву озбиљнију колекцију PDF датотека за приватну или професионалну употребу.
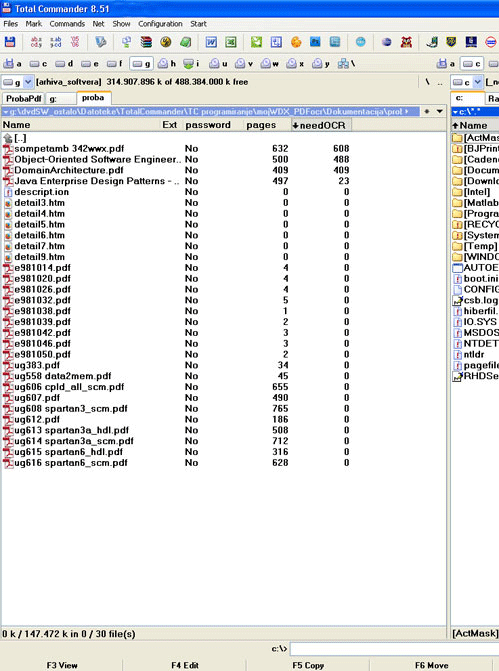
pdfOCR је мој додатак за најбољи уређивач датотека на Мајкрософт платформама (TotalCommander) који вам омогућава да у TotalCommander-у прикажете која од PDF датотека треба да се обради у OCR софтверу како би постала доступна за претраживање информација. pdfOCR у колони “needOCR” приказује колико скенираних страница (нечитљивих од текст претраживача) има PDF датотека у TotalCommander-у.
На приказаној слици на пример, датотека "Java Enterprise Design Patterns" од укупно 497 страница, није заштићена лозинком, има тачно 23 странице које нису претворене у текст и не могу се претраживати у претраживачима текста. Оваква датотека не мора да се обрађује у OCR софтверу јер је број страница за конверзију мали и вероватно је одређен сликама које и треба да остану слике. Са друге стране, прва горња датотека у списку има 608 од укупно 632 странице које су слике, па је очигледно да овде није рађен OCR поступак и да га свакако треба применити ако желимо да претражујемо информације те датотеке.
Детаљан опис овог додатка налази се на веб локацији totalcmd.net, и за не-комерцијалну употребу можете га преузети.
22.12.2014